Jeszcze niedawno, żeby prognozować wezbrania wód w rzekach, trzeba było mieć deszczomierz, wodowskaz, trochę wiedzy o zlewni i lata pomiarów, których rozdzielczość rosła z biegiem lat. Dziś coraz częściej wystarczą algorytmy i dane nigdy przez nas nie zmierzone.
AUTORZY: Hubert Jamry, Marcin Wdowikowski. Politechnika Wrocławska, Wydział Inżynierii Środowiska.
Według Światowej Organizacji Meteorologicznej powodzie błyskawiczne stanowią aż ok. 85 proc. wszystkich zdarzeń powodziowych na świecie i mają najwyższą śmiertelność spośród zagrożeń hydrologicznych. Nic więc dziwnego, że to właśnie one stają się poligonem doświadczalnym dla sztucznej inteligencji, która obiecuje stworzenie globalnych systemów ostrzegania, działających nawet tam, gdzie nie istnieje żadna infrastruktura pomiarowa. Najnowsze badania pokazują jednak, że między obietnicą a rzeczywistością wciąż istnieje istotna luka i tylko od nas zależy, czy będzie to szansa czy zagrożenie.
Powódź błyskawiczna ma w sobie coś z paradoksu. Jest jednym z najlepiej opisanych zjawisk hydrologicznych, a jednocześnie jednym z najtrudniejszych do prognozowania. Wynika to nie tylko z jej gwałtowności, ale też z lokalnego charakteru. W ostatnich latach w Polsce coraz częściej mówi się właśnie o punktowych zdarzeniach, związanych z intensywnymi opadami deszczu, które mimo niewielkiej skali potrafią powodować poważne straty, szczególnie w terenach zabudowanych i obszarach górskich. Co istotne, nie zawsze decyduje tu wyłącznie klimat. Równie ważną rolę odgrywamy my, uszczelniając powierzchnie naturalnego spływu wód, zabudowując doliny rzeczne i ograniczając retencję. W efekcie ta sama ulewa, która kilkadziesiąt lat temu zostałaby wchłonięta przez glebę, dziś zamienia się w gwałtowny spływ powierzchniowy.
Na tym tle za rewolucyjne należy uznać podejście zaproponowane przez zespół Google Research, które zamiast opierać prognozę na danych hydrologicznych, tworzy modele uczące się na podstawie zdarzeń z zachowaniem czarnej skrzynki (w znacznym uproszczeniu bez „zaglądania”, co dzieje się w środku) analizującej milionów przypadków i wariantów powodzi zmieniających się w czasie i przestrzeni. Co ważne, oprócz danych hydrologicznych i meteorologicznych analizowane są dane i informacje pochodzące z artykułów prasowych i komunikatów służb przetworzonych przez modele językowe, w tym model LSTM (ang. Long Short-Term Memory). W udostępnionym eksperymencie walidację wyników przeprowadzono w oparciu o dane z bazy GDACS (Global Disaster Awareness and Coordination System). W praktyce oznacza to zmianę klasycznego pytania „ile wody popłynie?” na rzecz sekwencji pytań „czy, kiedy, gdzie i jaka wydarzy się powódź?”. Wynikiem jest prawdopodobieństwo wystąpienia zdarzenia w ciągu 24 godzin. Co istotne, proponowane narzędzie działa globalnie i nie wymaga lokalnej kalibracji, obejmując obszary zamieszkane przez większość populacji świata.
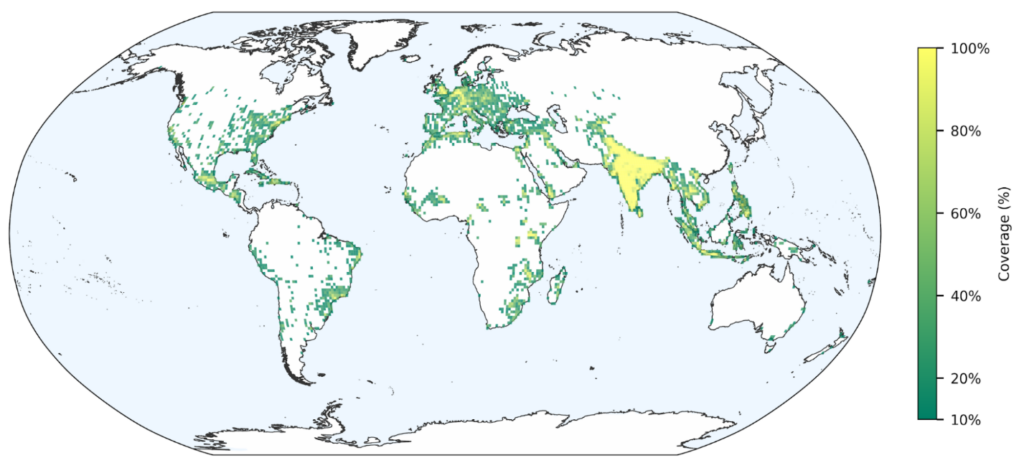
To podejście po części wpisuje się w szerszy i globalny już trend integracji danych obserwacyjnych i modeli sztucznej inteligencji. Jak pokazuje przegląd opublikowany w Remote Sensing, współczesne systemy monitoringu powodzi coraz częściej łączą dane satelitarne (SAR, optyczne), modele terenu (DEM, LiDAR) oraz algorytmy uczenia maszynowego. Dzięki temu możliwe jest nie tylko szybkie mapowanie zasięgu zalania, ale także – przynajmniej częściowo – estymacja głębokości wody i ocena skutków w środowisku zurbanizowanym. Kluczową rolę odgrywa tu synergia – satelity dostarczają informacji o stanie rzeczywistym, a AI przyspiesza ich interpretację i uogólnienie. Jednak rozwiązanie Google wydaje się być krokiem naprzód i próbą stworzenia globalnego systemu prognozowania bez konieczności posiadania lokalnych danych hydrologicznych i meteorologicznych (lub uwzględniając ich okresowy brak np. podczas awarii). Ale czy rzeczywiście działa tak dobrze, jak sugerują autorzy?
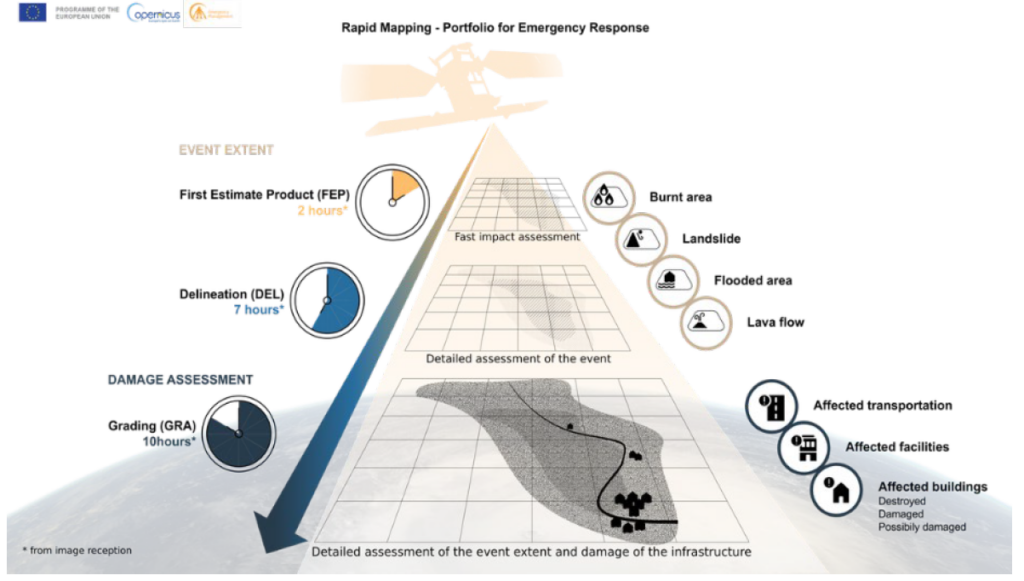
Krytyczny głos wobec zachwytu nad AI w hydrologii i systemach ostrzegania reprezentują hydrolodzy z USA, Kanady, Australii i Holandii. W artykule „When are AI models ready for deployment? Reassessing Google’s global AI flood forecasting system through the lens of responsible modeling” zwracają uwagę, że deklarowana skuteczność modeli AI może być przeszacowana, a wyniki silnie zależą od przyjętych metod oceny. Po zastosowaniu bardziej rygorystycznych kryteriów okazuje się, że modele mogą generować dużą liczbę błędów lub co gorsza fałszywych alarmów, jak i niewykrytych zdarzeń. W kontekście systemów ostrzegania to problem fundamentalny, bo zbyt częste alarmy prowadzą do ich ignorowania, a brak ostrzeżenia do realnych strat. Przy czym należy podkreślić, że wydajność modeli AI to stan na dziś, a tempo rozwoju rozwiązań opartych na AI nie wyklucza istotnej poprawy w dającej się przewidzieć przyszłości.
W efekcie sztuczna inteligencja nie tyle rozwiązuje problem prognozowania powodzi, co przenosi go na inny poziom. Z jednej strony daje narzędzia do globalnego monitoringu i szybszego ostrzegania, z drugiej ujawnia znaczenie odpowiedzialnego modelowania, walidacji i zaufania. Dla Polski to pytanie nie jest już teoretyczne. Dysponujemy rozwiniętymi systemami obserwacji i modelowania, ale jednocześnie coraz częściej mierzymy się z lokalnymi, intensywnymi zjawiskami opadowymi, które trudno uchwycić klasycznymi metodami. Być może właśnie w tej przestrzeni, pomiędzy radarowym pikselem a miejską zlewnią, sztuczna inteligencja znajdzie swoje miejsce, które pozwoli przyspieszyć reagowania na zagrożenia. I tu pojawiają się dwa kluczowe pytania: czy jesteśmy gotowi wykorzystać ten potencjał lub właściwie zidentyfikować zagrożenie i czy chcemy być użytkownikiem czy współtwórcą?